Databases (VITMAB04)
2023
Facts and Learning Tips
Databases will be one of the hardest subjects you have encountered during your studies. Although decades of experience suggests that the only thing needed to pass (with flying colors) is willing to obtain the knowledge presented to you during the course. Trust me, the knowledge you get here is basically a full-stack slice of THE system engineering skillset, which can be directly applied in the industry. During the semester, me and my colleagues attemp to give you a profound knowledge of both practice and theory. This includes the tech skills introduced during lab sessions, but dives down all the way to database theory including high-level structural modeling, physical storage considerations, algorithms and detailed answers for many “why”-s. So now I’m giving you the “how”: some tips and best practices for being a successful student of Databases:
- Study every single week. For each lecture, practice and lab, you should be familiar with the whole material of the lectures presented to you at that given point in time. You also have to be familiar with the relevant sections of the reference book. Do not be surprised, if the quiz or midterm or exam asks for knowledge not discussed in class, but discussed by the reference book. During (self-)studying, your instructors are open to discussion via e-mail in case you don’t understand something.
- Knowledge does not mean being able to recite the material word-by-word. Reciting the material word-by-word is completely useless in this course, as it is not what makes a good engineer.
- Knowledge means having a deep understanding of the material, seeing the connections between its different parts, and knowing the answer for all “why”-s. This knowledge can be obtained by trying to explain the material at home, in front of the mirror, to your teddy bear, your friend or roommate: Do this out loud, and while doing so, you will hear yourself and sense which parts are missing and have to be worked on.
- Knowledge also means being able to apply your knowledge. For this, doing all the tutorial exercises, doing the whole exercise book, and checking it with your tutorial instructor is a very good way.
- It is OK to be wrong. It is a valuable and necessary step in any learning process.
- It is OK to ask. As being wrong is OK, don’t be afraid to. All your questions will be appreciated! Ask during lectures, ask during tutorials, ask during labs or ask via e-mail: We are there to help and answer. Actually, that is why we’re there.
- It is not okay to pretend you understand while you do not. Feel comfortable to stop the class at any time and ask any question. There is no such thing as dumb question. All questions are valuable!
- As the goal is a profound and practical knowledge, the tests will contain exercises for checking this. Test exercises might greatly differ from the ones in class, but will need the same skillset and knowledge.
- A prerequisite of this course is to speak, comprehend and read English fluently. If you feel you are not there yet, do drop the course, spend the same amount of time improving your English skills, and come back next fall. Background: This course is the so-called “mirror course” of the Hungarian Databases course. You will get the same degree eventually, so you have to meet the same requirements to pass Databases. Hungarian students speak Hungarian fluently, so you have to speak English fluently to avoid language skills from being a barrier of your Databases studies.
Material
Reference book. This is the book you have to self-study at home besides the class material. The relevant sections are defined below.
PPT presentations:
- Intro (read this if you missed it in the first class): HERE
- ER: Material here
- Query optimization: Material here
- Transaction management: Material here
The rest of the topics do not and will not have PPTs. (This is a choice of the lecturer.) For these and basically all topics, use the reference book and more preferably your own notes made during lecture. (THe book does not contain the query optimization topic.)
Exercise book. If you do every single exercise, and discuss your questions with your instructors, your chances of getting a good grade will significantly improve (as decades of experience suggests).
Here are the recordings of last year’s Databases lectures and tutorials. The ones relevant for you are the ones under my name. “Databases, Lecture n” is the nth lecture, “Databases, Practice m” is the m tutorial session. Also, there is a “Databases, 7,5th Lecture”. Don’t miss that one. Note: These videos only cover like half of the complete material!
Lectures
Lectures are held every Monday from 14:15 to 15:45. Location: IE.220
On week 1 there will be an extra lecture on Thursday, september 7th at 16:15, in room QBF.11.
On week 2 there will be an extra lecture on Thursday, september 14th at 16:15, in room IE.220.
Then all further lectures will be on Monday.
Topics and corresponding sections in the reference book:
-
ER modeling: p32-42. Notes for the ER modeling chapter of the book:
-
disregard p33/paragraph 2., as we don’t talk about object-oriented data modeling
-
The book uses the term “relationship set” the same way as our course does. However, the book uses the word “relationship” as a synonym of “relationship type”, which describes which entity sets are connected by the given relationship type. According to the book, the instances of a relationship (type) are all the exact representations of the given relationship type, which are relationship sets, where each relationship set contains different connections among the entities of the connected entity sets. This terminology of the book is a very nice, mathematically fair and consistent. However, in this class, we will use an rather lightweight terminology, where:
-
a relationship denotes an element of a relationship set, i.e. a relationship defines a connection among a pair of (or set of) entities (i.e. entity set elements)
-
a relationship set is the set of all relationships of the same semantics. There is only a single relationship set of the given semantics, and its elements (the relationships) may change by time
-
So whenever the book refers to a “relationship”, it means “relationship set” in the terminology of our course. Some exact cases (not all of them) will be mentioned below.
-
-
As a consequence of the above, on p36, the first paragraph under section Relationships is adjusted to the terminology used in this course as follows: “A relationship set among entity sets is an ordered list of entity sets. A particular entity set may appear more than once on the list. If there is relationship R among entity sets E1, E2,…, Ek, then the current instance of R (i.e. the current relationship) is a set of k-tuples. Each k-tuple (e1,e2,…,ek) in relationship set R implies that entities e1,e2,…,ek, where e1 is in set E1, e2 is in set E2, and so on, stand in relationship to each other as group. The most common case, by far, is where k=2, but lists of three or more entity sets are sometimes related.”
-
In Example 2.4 MOTHER_OF is a relationship set itself, not a relationship. (p1,p2) is a relationship (instance).
-
In section “Entity-Relationship Diagrams”, under 3, “Diamonds represent relationship types” according to our terminology.
-
When the book writes about “Functionality of Relationships”, according to our terminology, it writes about “Functionality of Relationship Sets”
-
Also note that “isa relationship” is separate from the notion of “relationship”, as an isa relationship is defined between entity sets and not entities.
-
Note that the concept described in the “Borrowed key attributes” is the same as that of weak entity sets, except for the final example of the section about multiple citizenships: the toolset used in this course does not directly support modeling such cases.
-
- relational data model: p43-65
- On page 49, in point 4 (top of page) k=1 that is, there is only a single entity set on the ‘many’ side of the relationship set, as we only define cardinality (functionality) for binary relationship sets. In conclusion when mapping a many-to-one (binary) relationship set to a relational scheme, the key of the relational scheme will be the key of the entity set on the ‘many’ side.
- Physical organization: p294-330 (Section 6.7 is not needed)
- skip the part from section “Variable-Length Records” on p300, all the way to the beginning of section 6.2 on p304 (Section 6.2 is needed)
- skip the part from section titled “Sorted Files with Pinned Records” on p318, all the way to the beginning of Section 6.5 on p321 (Aection 6.5 is needed)
- you can read Section 6.13 (p358) for fun (will not be part of midterm or exam)
- you might want to read Section 6.8, but in lecture we will have a more concise discussion on this (and we will only use dense indices for second indices)
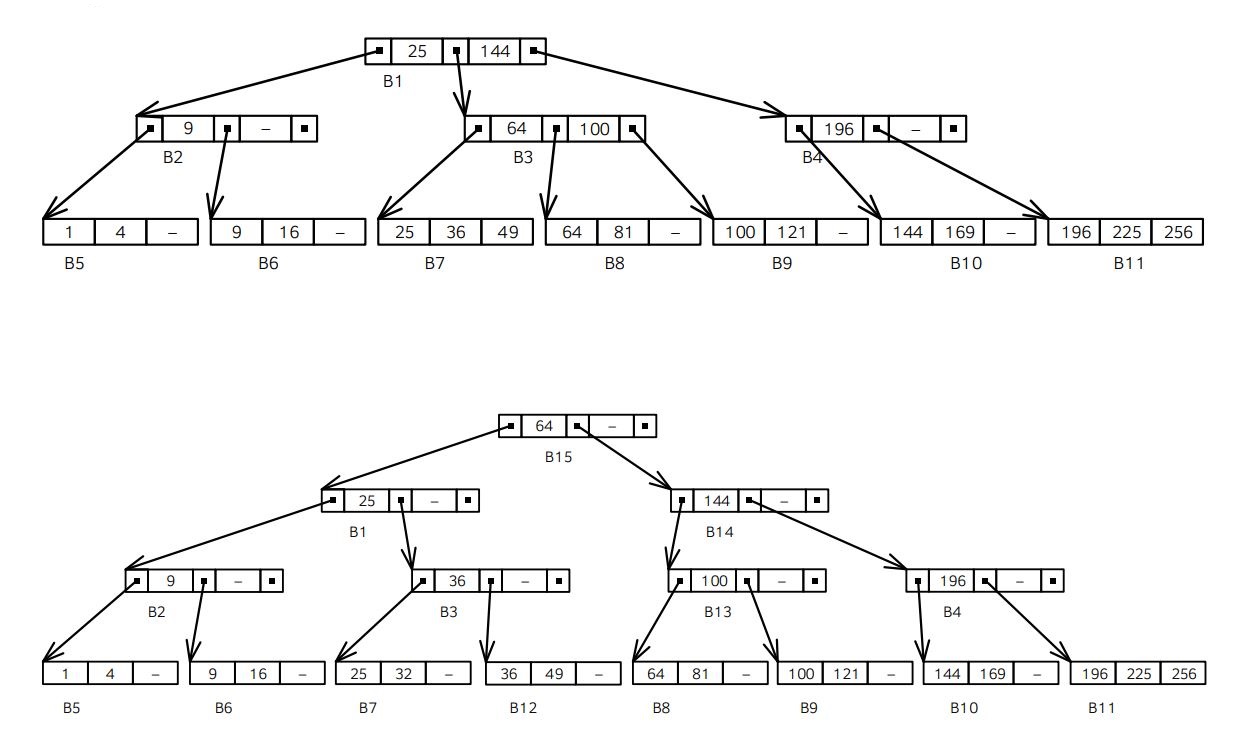
- B*-tree example here
- Query optimization: See PPT
- Transaction management: p467-543
- Section 9.6 is not needed, subsection “A Conservative Protocol” starting on page 512 is not needed, but the main idea from it (requesting all needed locks at once) is needed.
- Design theory: p376-390 plus section 7.6
- p390 is needed until the section Minimal covers (which is not needed)
- please note that the lecture covers more of this topic than the book.
{kind=link}
Instructors
- Levente Erős, eros -AT- db.bme.hu
- Ruba AlMahasneh, ruba.mahasneh -AT- db.bme.hu
Evaluation of results
A single midterm test will be written. Passing the midterm test is a requirement for the signature. One retake is possible in case of failure on the midterm test.
Furthermore, there will be a quiz (10 minutes) in class after each (sub)topic. You will be notified about the next quiz in the previous lecture. Quizzes are discussed right away (5 minutes). Quizzes and their discussion take 15 minutes at maximum. Further discussion is possible after class or via e-mail. The purpose of quizzes is to serve as a feedback for you on how clear you are with the material and how much you are on the good path on passing the midterm test or exam. Quizzes act as a “progress bar” if you like. Quizzes generally do not influence the signature or the final mark, but might convince me to or not to round your final mark up in case you are in between marks.
Your final grade is calculated as follows: For each lab, you get a lab grade, depending on the grade you got for your work from the evaluator, and your classwork in lab. Note: Your grade for each lab will be assigned by your lab instructor. The evaluator only grades the work you handed in. The lab instructor has the right to give a different lab grade.
You will get 4 lab grades in total (for the labs, except for the Team Workshop), which will be averaged (let’s call this lab average L). Each of your lab grades must be greater than or equal to 2 to get the signature. A single lab can be retaken in case of failure. If you fail 2 labs or more, you will not get the signature. Failing a lab entry test makes you fail the given lab.
The prerequisites of the signature are thus: Passing the midterm (or the midterm retake), and passing all labs.
If you have the signature, you can take the exam. You also get a grade for your exam. Let E denote this grade. E must be greater than or equal to 2.
Your final grade, registered in Neptun will be 0.6E+0.4L.
Your performance on the Team workshop might increase your final mark.
Tutorials (practices)
Tutorials are held on Thursdays, from 16:15 to 17:45 in room IE.220 (take the triple elevator to the 2nd floor), according to the following schedule. You should prepare for these classes, from all preceding lectures.
Instructor
- János Varga, real.janos -at- gmail.com
Material and dates
Please make sure you have this open at the beginning of each practice.
| Topic | Date | Exercise sheet |
|---|---|---|
| LECTURE | Sep. 14 | - |
| ER Modeling | Sep. 28 | HERE |
| Relational Queries | Oct. 12 | HERE |
| Physical Storage | Oct. 26 | HERE |
| Query Optimization | Nov. 9 | HERE |
| Normalization | Nov. 23 | HERE |
| Transaction Management | Dec. 7 | HERE |
Laboratories
Instructors and contact
Lab responsible:
- Ruba Mahasneh, ruba.mahasneh -AT- db.bme.hu
Lab instructors:
- András Gerendás, gerendas.andras -AT- db.bme.hu
- AlGhaith Ahmad, alghaith.ahmad -AT- edu.bme.hu
- Tatiana Barbova, tatiana.barbova -AT- edu.bme.hu
- Chaitanya Arora, chaitanya.arora -AT- edu.bme.hu
- Dhoioui Oussama, dhouioui.oussama -AT- edu.bme.hu
Place of labs
For the Team Workshop EVERYONE go to TODO
For all the other labs, do as described below:
- If your NEPTUN ID starts with A, B, C, D, E, F, G, or H then go to room R4O. Your lab instructors are András Gerendás and Chaitanya Arora
- Otherwise, go to room R4P. Your lab instructors are Tatiana Barbova and Dhouioui Oussama.
Time of labs
Each lab is on Thursday, from 16:15 to 17:45, according to the following schedule:
| Topic | Date |
|---|---|
| Oracle | Sep. 21 |
| SQL I | Oct. 5 |
| SQL II | Oct. 19 |
| SQL III | Nov. 2 |
| Team Workshop | Nov. 30 |
The Team workshop will be in room QBF.11.
General information
You should arrive at the lab prepared from the course material. At the beginning of each lab, an entry test will be written which is necessary for completing the given lab practice. The course material can be found below for each topic, separately.
You will start solving the exercises during class. The amount of exercises that you get can be solved within a single class if you are prepared. Once finished, you can upload your solutions in a predefined format (see below) in the lab portal, which is here. You always have to submit a lab report and in case of some labs, additional files too (see below). If you can’t finish the exercises during class, you can finish them at the Students’ Computer Center (HSZK, floor 4, building R), or at home, but 48 hours after the beginning of the given lab, your solution has to be uploaded. The deadline is thus, Saturday, 16:15.
The labs are equipped with the hardware and software needed for the classes. Using your own computers during labs is allowed, although we cannot give support for installing/configuring or troubleshooting the necessary tools on your laptops.
Lab report requirements
Each student has to submit a unique lab report about the work performed in the lab, which contains the unique solutions of the given student along with the underlying logic of the solutions. The lab report should thus, be a high-quality technical documentation of the work performed, and the evaluator of the report should be able to trace the student’s chain of thoughts that led to the solution. You can use this template for your lab report.
- Not meeting the below requirements might yield in score deduction or failing the lab.
- The header of the lab report should be precisely filled out.
- The exercise text should not be in the lab report.
- Only include the numbers of those exercises that you have solved.
- References (link, images, source code):
- Put all the references to the footer (if there are references). To avoid plagiarism, you should indice the source of everything that is not your own product (e.g.: Stackoverflow).
- Images should be placed close (above or under) the eplanation. If this is not possible, give them a number and reference them by this number
- Only use easily readable, good quality pictures in the document.
- Source code or text output – if needed for the documentation – must be included as text content. Screenshots in this case are not allowed.
- Explanation:
- Do not include unexplained source codes or images without explanation. Evaluators will account these as non-existent.
- In case of an image, describe what can be seen on the image.
- In case of code, explain what the code does.
- In the explanation, include how you got to the solution!
- If you tried something out that didn’t work, you can document it, as it was part of the way to the solution.
- Your goal is to convince the evaluator about the correctness of your solution. Thus, pay attention to your spelling, and professionalism, phrase your sentences so that they are easily understandable. THe evaluator should be able to reproduce your work based on your documentation.
- The correctness of your solution shall be proven by testing, as without this the evaluator might think you handed in a solution that you haven’t tried out.
- Do not include unexplained source codes or images without explanation. Evaluators will account these as non-existent.
- You should submit a PDF file from which it is easy to retrieve (copy) the textual contents.
Software you will need
- Oracle SQL Developer 4.2.0. To run it: Unpack it, and execute sqldeveloper\sqldeveloper.exe. If it does not work, then run sqldeveloper\sqldeveloper\bin\sqldeveloper.bat. This is for Win64. You’ll need JRE to run this.
- For other platforms, you can download the same version of SQL Developer here. You’ll need to install the appropriate Java 8 JDK to run this. Attention! On Oracle’s website, SQL Developer 18.1 stable can be downloaded since April 5th 2018. However, in the lab we will use version 4.2. We are unaware of any significant issues caused by the differences between versions, but should there be any issue due to this, we might not know the solution. So please, use version 4.2
The work environment is provided and supported in HSZK.
Network settings for home
SQL Developer connection:
- Hostname: rapid.eik.bme.hu
- Port: 1521
- SID: szglab
Useful material
- Preface of the course material
- UNIX summary
- Oracle SQL Reference
- Oracle SQL quick reference
- ER cheat sheet
- LucidChart
Lab 1, Oracle
Please prepare from the following PDF:
Your exercise sheet can be downloaded from here.
You should upload a single PDF file to the lab portal, containing your report. The name of the file should be NEPTUN-1-c16.pdf, where you should substitute NEPTUN with your actual NEPTUN code.
Below is the SQL code that has to be executed after solving exercise 5.
-------------------------------------------------
-- SQL code to be executed in the 5th exercise
-------------------------------------------------
column grantor format a8;
column grantee format a8;
column table_name format a20;
column privilege format a20;
select grantor
, grantee
, table_name
, privilege
, initcap(grantable) grant_opt
from all_tab_privs
where grantor = user
or grantee = user
order by grantor, grantee, table_name, privilege
;
Labs 2, 3, and 4: SQL1, SQL2, SQL3
The material for the SQL labs (SQL1, SQL2, and SQL3) can be found here. The appendix about SQL constraints is here
- For the first SQL lab, you should be prepared from table definition, data manipulation statements and from the ER modeling and ER->relational mapping chapters of the Databases course.
- For the second SQL lab, you should be prepared from SQL queries.
- For the third SQL lab, you should be prepared from the entire SQL guide.
For the requirements of completing this lab, and for some SQL tips, read this Students’ guide!
The skeleton of the script to be handed in is here, while here is a page that helps you create the XML file if you don’t do it manually.
USING THE GENERATOR PAGE IS PREFERRED. PLEASE NOTE THAT IF YOUR SCRIPT DOES NOT GENERATE A WELL-FORMED XML OUTPUT, YOU WILL FAIL.
To check whether your output is well-formatted, do the following:
- clean your script output in SQL Developer (rubber icon)
- run your SQL script using F5
- save the output to an XML file
- open your XML file with your browser. There if you see the hierarchical structure, and the different tree nodes can be extended and collapsed then it is well-formatted. If you need help with this versification, reach out to your instructors.
SQL 1 sample file is here
Lab 5, Team workshop
Before you join this workshop, make sure you are familiar with all of the material already covered in the lectures, tutorials and previous labs. Exercises will only be shared with you during the lab.
Also, read THIS material about data flow diagrams.
Are you ready for a challenge?
Choose your teammates (3 or 4), then the first two teams to deliver the correct solution will be entitled to upgrade their final grade.
The aim of this workshop is to facilitate discussions and activities to explore ER modeling by solving two real-life use cases. The only way you can claim the extra marks is by finishing the two case studies within the lab time. The first 10 minutes will be dedicated to the instructors explaining (going over) the use cases and to sharing the link were you can download them.
Then the competition beings!
Note: All the teams will be able to view the solutions, as they will be posted on the portal after the lecture.
SQL exercises
In order for you to be able to try writing SQL statements before the lab, and gain some practical knowledge, I made for you a script and some exercises you can do before the labs.
To initialize the environment, run this script in SQL Developer. This creates two tables and fills them up with data you can work on. Then, query the following:
- The name of each person.
- People and cars belonging to them.
- People without cars.
- Car types and number of owners of that type.
- People and number of cars they have in descending order of number of owned cars.
- People and number of cars they have, including those without a car (i.e. having 0 cars). Rows should be ordered by the number of cars owned, in ascending order.
Create a table storing which person drove which car (not necessarily their own) and when.
Insert example data into this newly created table. Try to insert data belonging to a nonexistent person or car. Do you get an error message? If not, create the appropriate constraints, which you have not created yet.
Have fun!
Midterm
November 14th from 8:15, location: E.1.B
Retakes
Midterm retake: November 28th from 8:15, location: E.1.B.